
Web Scraping Basketball Reference
In this post, you'll learn how to scrape player data from basketball-reference.com using Python.
I first became interested in statistics and data science because of my love for basketball. In the NBA, data is ubiquitous, and it’s becoming more influential in managers’ and coaches’ decision making. Each basketball game has a resulting “box score”, a table displaying descriptive numbers about the game at a team and player level (e.g. points scored, field goals made, rebounds, time played). Over the course of a season, a player’s performance can be measured and tracked through the aggregation of these box scores. Basketball Reference stores this insightful data for each player that has ever played in the NBA.
I’ll explain how to scrape this data from the web by doing the following:
- Discuss unique website structure and path to the data.
- Display code that scrapes the data and organizes it into a pandas dataframe.
Website Structure
Target Table
Here’s a look at one of the data tables I’m looking to scrape from the site:
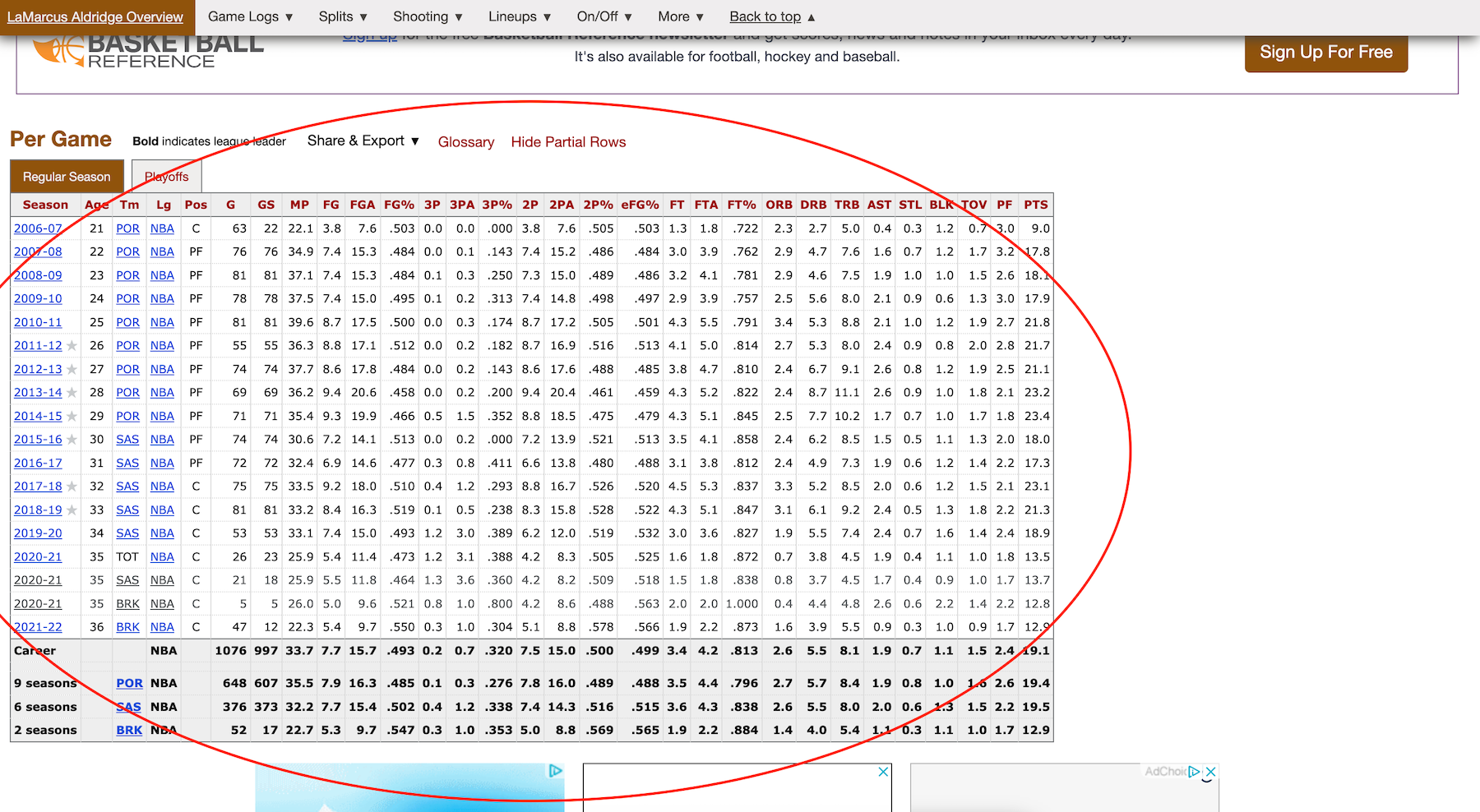
This table represents the data over all available seasons for just one player–LaMarcus Aldridge. What I’d like to get is data for all 859 active players in the NBA. Because each player’s data table is on an individual page, my code will have to hit all 859 pages to do the necessary scraping. So, where can I get a list of all the pages I need to hit? Take a look:
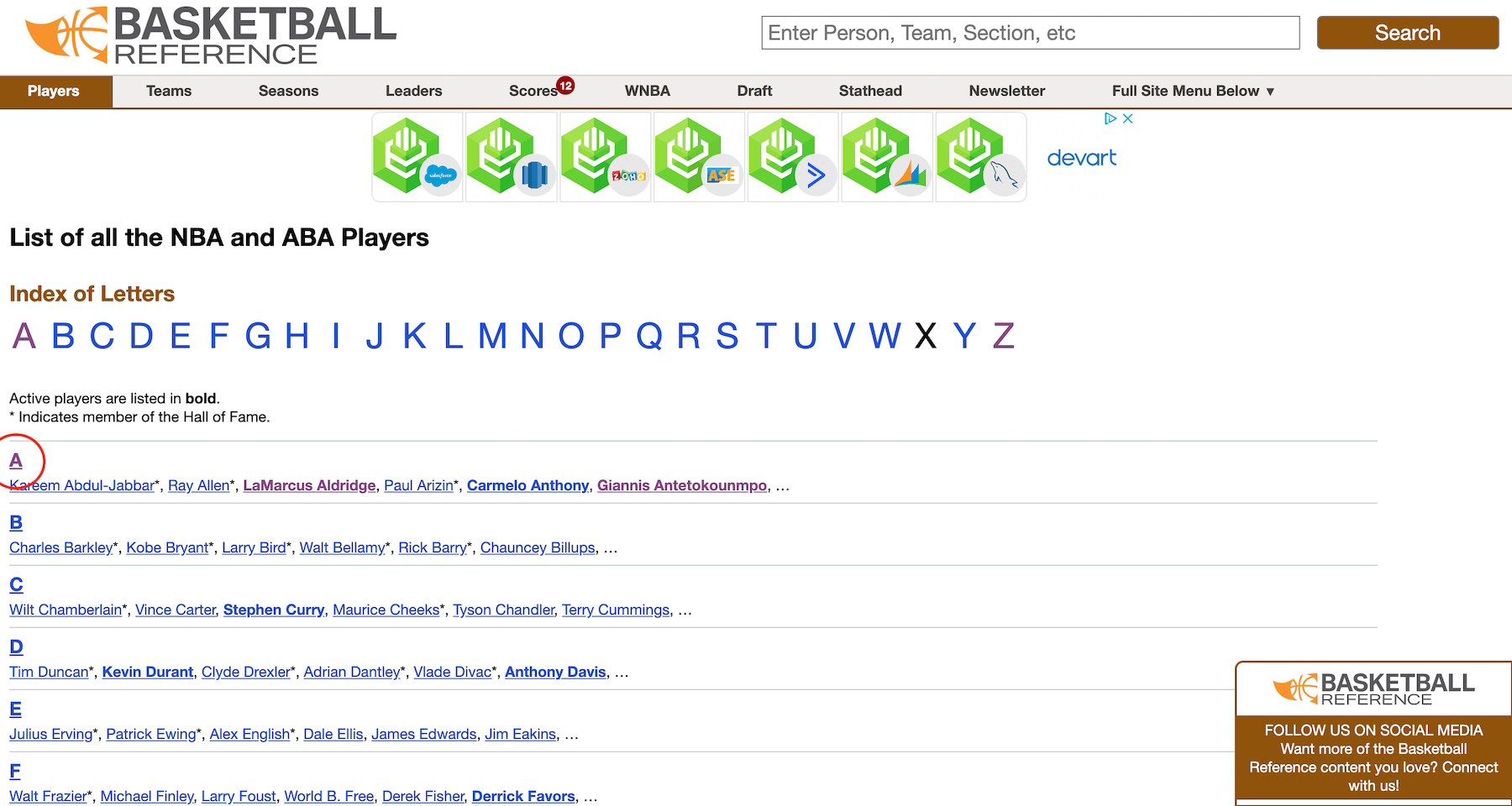
As you can see, this directory page contains links to each player page, categorized by last name. When I click on the link for all those with a last name beginning with A, here is what I see:
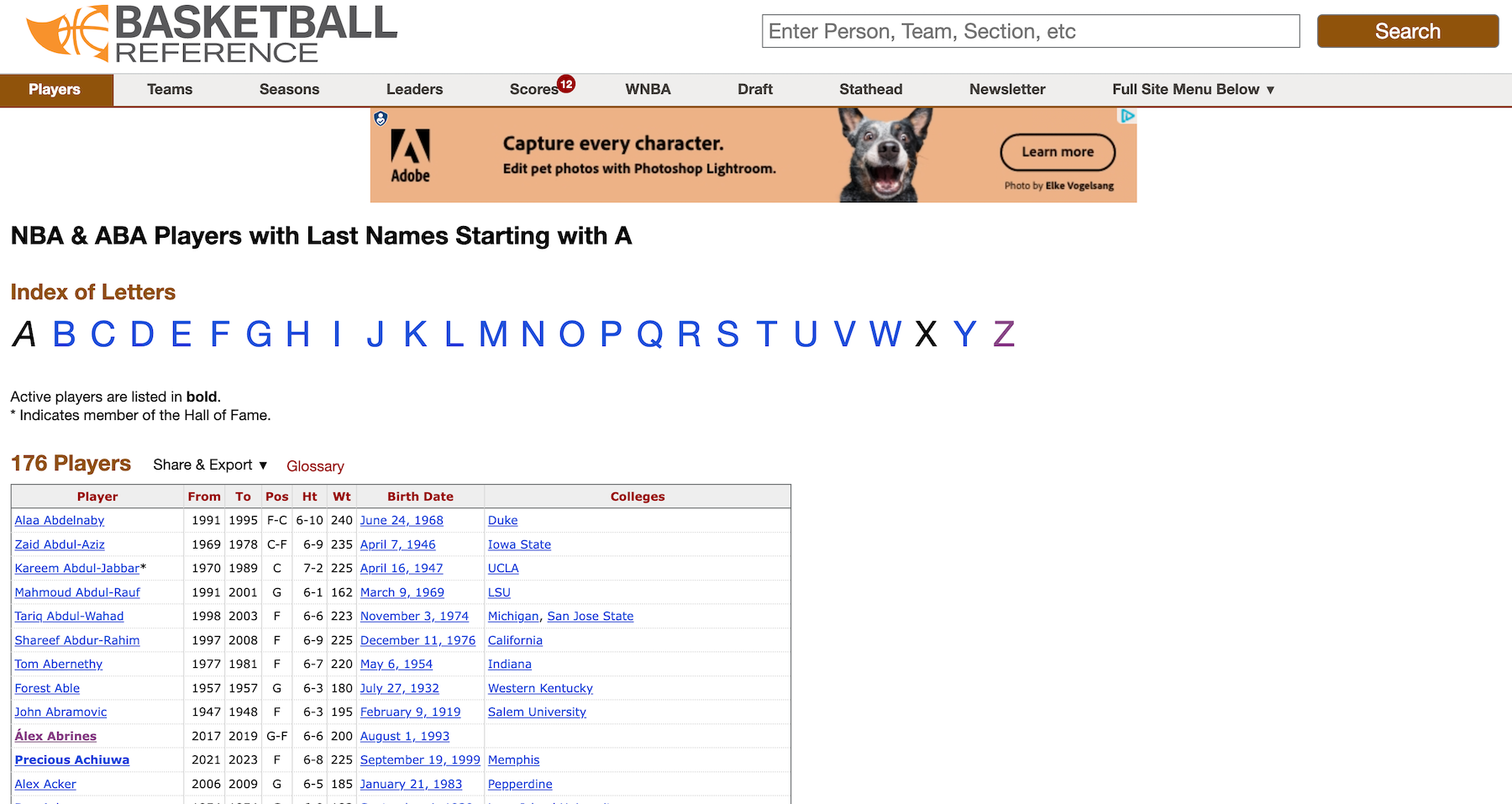
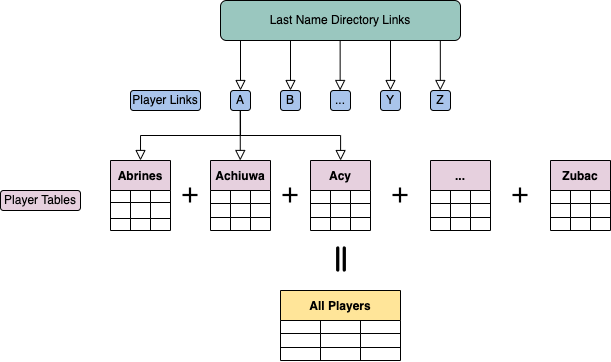
On this page, each player’s name is a link to their individual page where the target table resides. So, my scraping code will contain three components:
- Get links to all last name directories.
- Get links to all individual pages.
- Get target table from each individual page.
Then, once I get each target table, I can combine them together to create one large dataframe.
The Code
Packages
- pandas: to build pandas dataframe with player data
- requests: to import website html code/info
- BeautifulSoup: to navigate html code to desired data
import pandas as pd
import requests
from bs4 import BeautifulSoup
Scraping
Get links to all last name directories:
# get all last name directory links
# links found in 'ul' tag with 'page_index' class
# directory links will have a text with length 1 (e.g. "A")
# base url must be added to directory path
letter_links = bs.find('ul', {'class': 'page_index'}).find_all('a')
letter_links = ['https://www.basketball-reference.com' + link.get('href') for link in letter_links if len(link.text) == 1]
Get links to all individual pages:
# get all player links from last name directory links
# initialize empty list of player links
player_links = []
# player links found in 'th' tag w/specific scope and class
# active players with 'strong' tag
# add base url
for letter_link in letter_links:
r = requests.get(letter_link)
bs = BeautifulSoup(r.text)
player_tags = bs.find('tbody').find_all('th', {'scope': 'row', 'class': 'left'})
player_links += ['https://www.basketball-reference.com' + player_tag.find('a').get('href') for player_tag in player_tags if player_tag.find('strong')]
Get target table from each individual page, make dataframe:
# build dataframe of all players' stats by season
# initialize empty list to which dfs will be appended
appended_data = []
for player_link in tqdm(player_links):
# get tables from player page
dfs = pd.read_html(player_link)
# save df as second table in html table code
df = dfs[1]
# add player name as col
r = requests.get(player_link)
bs = BeautifulSoup(r.text)
name = bs.find("div", {"id": "info", "class": "players"}).find("h1").text
name = name.split('\n')[1]
df['Name'] = name
# add years of experience (use index + 1)
df['Exp'] = df.index + 1
# append individual df to list
appended_data.append(df)
# combine all dfs together
nba = pd.concat(appended_data)
Here’s what the head of your dataframe will look like if run correctly:
EDA Coming Soon
Next up, I’m going to be posting about an exploratory data analysis on this scraped data! Here are some questions I’ll be considering:
- Has the average age of a player in the NBA changed season over season? In other words, is the league becoming younger/older?
- At what age and level of experience do players hit their peak performance in key statistical areas such as minutes per game, number of games in starting lineup, points per game, field goal percentage, etc.?
- How is player performance impacted when switching teams?
- When is the biggest leap in player performance? Biggest drop?
What other aspects of the data do you think might be interesting to explore? Comment below with your suggestions.
Extra
Link to GitHub repo: https://github.com/shargyle/NBA-Analysis
Note on ethics: In the terms of service on Basketball Reference, it states that the data cannot be used to compete with the services that the site offers. Given that I’m using the data for analysis and do not intend on distributing it to anyone for the purpose of providing NBA data, I deemed it ethical to scrape data from the website.